Overview
This post describes how to set up a Microservices platform on AWS Fargate backed by an Aurora RDS Cluster using Cloudformation. It consists of three main Cloudformation stacks: A Fargate Cluster Stack, an RDS Cluster Stack and a Service Stack that builds on the previous two. A 4th Support Stack contains a collection of custom Cloudformation resources backed by AWS Lambdas. The Service Stack repeats for every Microservice.
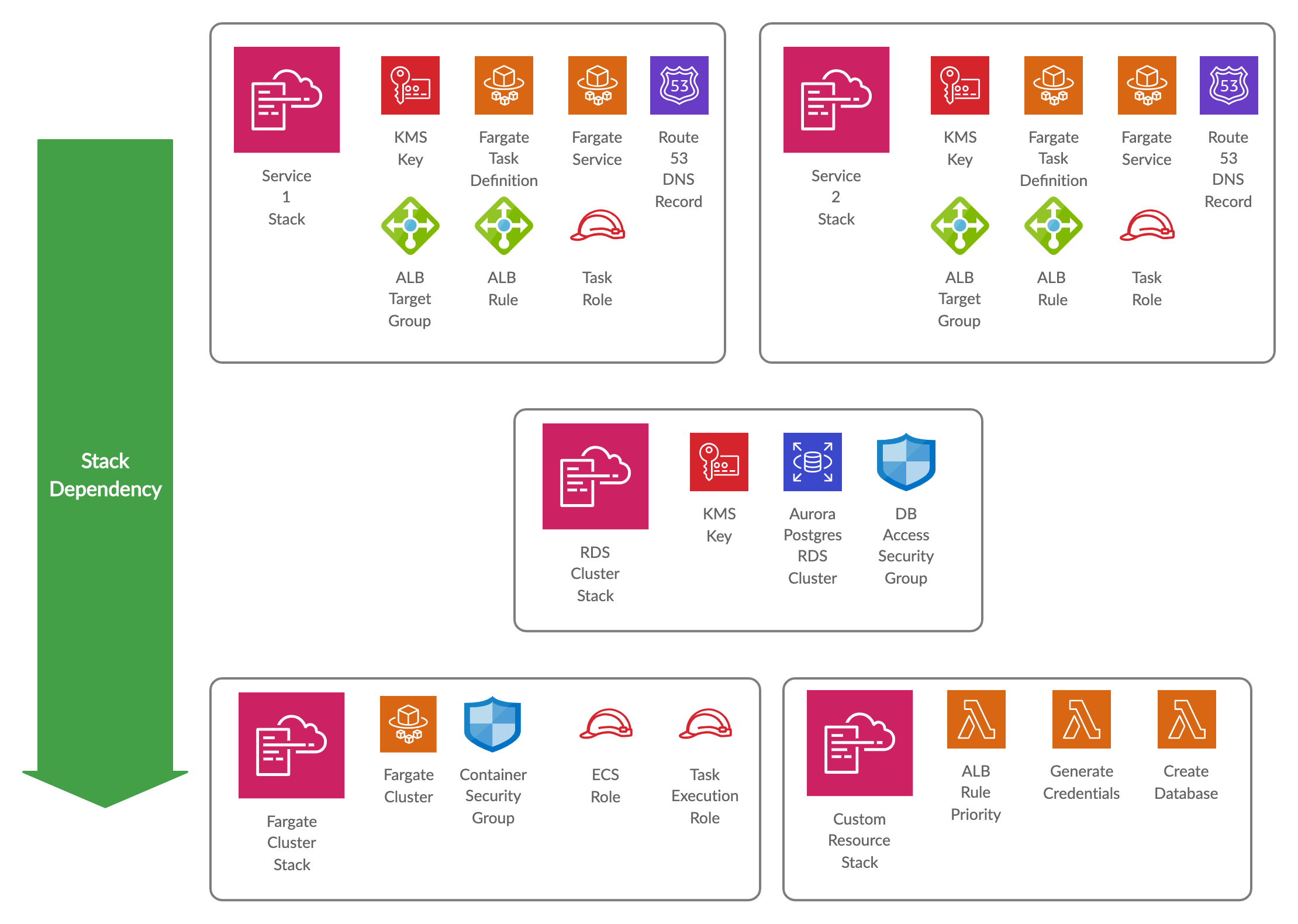
Fargate Cluster
AWS Fargate enables you to run Docker containers in the cloud without having to manage the underlying EC2 instances that make up the cluster. As application developers, we have to package the application in a Docker image and host that image in a place where Fargate can reach it, like Elastic Container Registry(ECR) for private images or Docker Hub for public ones.
Two important aspects of the Cloudformation stack creates the Fargate infrastructure, which will be used in other stacks that depend on it, is the container security group and the task execution role:
Fargate Container Security Group
The Container Security Group controls access to containers running on Fargate. Typically this includes network access from the Load Balancer and potentially allowing containers in the cluster to communicate, although I have found that inter-container communication usually happens via the Load Balancer. Secondly, the RDS cluster will permit network access from any container in this Security Group. Limiting network access to the database by only allowing certain Security Groups is better than say allowing an entire subnet or CIDR ranges.
Task Execution Role
Not to be confused with the Task Role, the Task Execution Role is what permits Fargate to perform actions related to running the container. These typically include permission to pull images from ECR and to forward logs to Cloudwatch. This role does not define what the container running on Fargate can access, that is the job of the Task Role.
The 3rd important aspect of the Fargate stack is internal, the ECS Role:
ECS Role
An IAM role which authorizes ECS to manage resources in the account is also required. Generally, this includes permission to modify the Elastic Load Balancer in terms of updating Target Groups. During deployment, Fargate will start the new container and then adjust the IP in the Target Group to that of the newly created container.
Aurora Postgres RDS Cluster
This example assumes a single RDS Cluster that hosts multiple databases, one for each Microservice deployed on Fargate.
Admin Secrets
One of the challenges when creating an RDS Cloudformation stack is how to create and store admin credentials for the cluster. This example makes use of a custom Cloudformation resource backed by a Lambda. The Lambda generates a random password and then stores it as a secure string in the Parameter Store, encrypted with a KMS key created as part of this Stack. The RDS Cluster resource references the password output from the custom resource.
A note about custom Cloudformation resources:
Any language supported by AWS Lambda can be used to create a custom resource. I have found that Python is a good fit. Javascript tends to be more challenging to get right with its async nature. One giant drawback of custom resources is that the Lambda has to perform a callback to Cloudformation with the result, failure to do so will cause the initiating stack to hang until a timeout occurs.
Custom Cludformation Resource to generate credentials
Database Access Security Group
A Security Group that defines network access permissions to the RDS Cluster. As mentioned earlier, this Security Group will permit the Fargate Container Security Group to access the RDS cluster, along with a Lambda backed custom resource that can create a database on the Cluster, which is discussed later in this post.
A second SecurityGroupIngress resource allows access from the Database Access Security Group to itself, permitting replication between the RDS cluster nodes.
Fargate Service
Task Definition & Service
The Task Definition and Service resources are required to deploy a container on Fargate. The Task Definition defines parameters for the Docker container including the CPU, memory, execution role, environment variables, port mappings and the log driver, in other words, the container configuration. The Fargate Service can be seen as an instance (or instances) of a Task Definition and defines the number of containers, security groups, the target Fargate cluster and the load balancer hosting the target group.
Every Microservice deployed on Fargate will have a Cloudformation stack. It defines the TaskDefinition with environment variables for the RDS Cluster host, port and the parameter store keys that contains the database username and password. The container can use these variables to connect its Database.
The Fargate Service resource also gets defined in this stack. Including the Service in the Fargate Container Security Group permits network access to the Database.
Fargate Task Definition & Service
This stack can define the Task Role, that grants permission to perform whatever actions the container requires, but it can reference the Task Execution Role created in the Fargate Cluster stack.
Creating a Database with Credentials
The Cloudformation stack contains another Lambda custom resource that creates a database and the credentials to access it as part of service deployment. The lambda generates a password and stores it as a secure string in the Parameter Store using a KMS key that gets created as part of this stack (Every service gets its own KMS key). After generating the credentials, it connects to the RDS Cluster and creates a database and role that has all privileges on that database using the generated credentials. Note that the lambda will only perform this action if the database/credentials do not already exist.
Create Database Custom Resource
The application has two options on how to retrieve the credentials, a startup script in the Docker container can use AWS CLI and pass it as arguments to the application or the application can resolve it at runtime, e.g. spring-cloud.
Schema setup/migration can be performed during application startup using tools like liquibase or flyway.
Load Balancer
A Target Group and Load Balancer Listener Rule are required to perform load balancing. The Target Group contains the IP addresses for all the containers started as part of the Service. For example, if the desired count on the Service is 2, then the Target Group will contain 2 IP addresses.
The listener rule tells the load balancer what kind of HTTP requests to route to the target group. Typically the host header is used, that means every Service will have a unique domain name (e.g. order-service.company.com). There is one challenge in automating the creation of listener rules, the rule priority. The priority needs to be unique. Yet another Lambda backed custom resource can solve the problem by looking up the max rule priority number and increment it.
alb_rule_priority.py
The last step is to create a Route53 DNS record for the service that points to the load balancer configured above.
Logging
The Fargate Service is configured to use the awslogs log driver, this will forward standard output from the container to Cloudwatch. There are 2 main considerations for logging, the first is to produce structured logs from the application, this will enable advanced log searching in Cloudwatch and also simplify log aggregation into tools like Kibana.
The second consideration is to mask personally identifiable information in the log output.
Sharing Deployment Template Between Services
Packaging the Fargate Service deployment Cloudformation template as an Ansible role enables easy reuse. Baking the Ansible role into an easily distributable Docker image means every service can have a deployment playbook that references the Ansible role and provides the parameters specific to that service. CI/CD servers that support Docker images as agents, like Jenkins can then use the deployment Docker image (with the ansible role) together with the playbook in the service to deploy the application as part of the pipeline.